Para el final de la sesión, el alumno comprenderá los fundamentos de la estadística inferencial. Asimismo, podrá calcular los intervalos de confianza de una media poblacional a partir del análisis de una muestra.
4.2 Presentación
4.3 Problema
En esta sección, abordaremos un problema que nos permitirá explorar y comprender más a fondo los principios de la estadística inferencial. Te pido que te enfoques en mantener la esencia de esta idea a lo largo del análisis, más allá del código específico que utilizaremos.
4.3.1 Población y muestra
Dada una población de 3000 individuos, el objetivo de este estudio es determinar la media de ingresos de toda la población. Debido a limitaciones de recursos, no es factible recopilar datos de todos los individuos directamente. En consecuencia, se procederá a realizar un análisis basado en una muestra representativa, con el fin de estimar la media poblacional de ingresos.
Importante
En este punto del curso es clave que hagamos la diferencia entre población (todas las unidades de estudio que deseo estudiar y no puedo alcanzar por diversos motivos) y muestra (pequeña porción representativa de esa población).
Este conjunto de datos representa nuestra población completa (denominado poblacion). Dado que no es viable calcular directamente la media de toda la población, nuestra metodología consistirá en extraer muestras. Para iniciar, procederemos con un estudio piloto extrayendo una muestra de tamaño 20.
Tenemos la población y tenemos la muestra. ¿Qué sigue?
4.3.2 Media muestral
Una vez obtenida una muestra representativa, y con el objetivo de estimar la media de ingresos de la población total, procederemos a calcular la media de esta muestra. Este cálculo nos proporcionará una estimación aproximada de la media poblacional.
Ojo, utilizaremos datos de la muestra de 20 casos, centrados exclusivamente en la característica de ingresos.
mean(muestra1$ingresos)
[1] 1558.204
A partir de los datos recopilados, hemos calculado que la media de ingresos de nuestra muestra. Esto nos permite inferir que la media de ingresos de la población total podría aproximarse a este valor.
Importante
Cuando utilizamos la media de una muestra como aproximación de la media poblacional, a este proceso se le denomina estimación puntual.
4.3.3 Varias muestras, varias medias?
Ahora bien,¿qué ocurriría si replicáramos este proceso en un universo paralelo? Procedamos a simular de nuevo la extracción de una muestra y el cálculo de la media muestral.
¿Qué conclusiones podemos extraer de esta nueva repetición?
Utilizaremos el código para replicar dos veces la extracción de una muestra de 20 personas y calcular la media de ingresos.
En este punto damos cuenta que si repetimos el proceso tendremos distintas medias muestrales. Por lo que contar con estimadores puntuales puede resultar poco consistente.
4.3.4 Un patrón interesante: Teorema del límite central
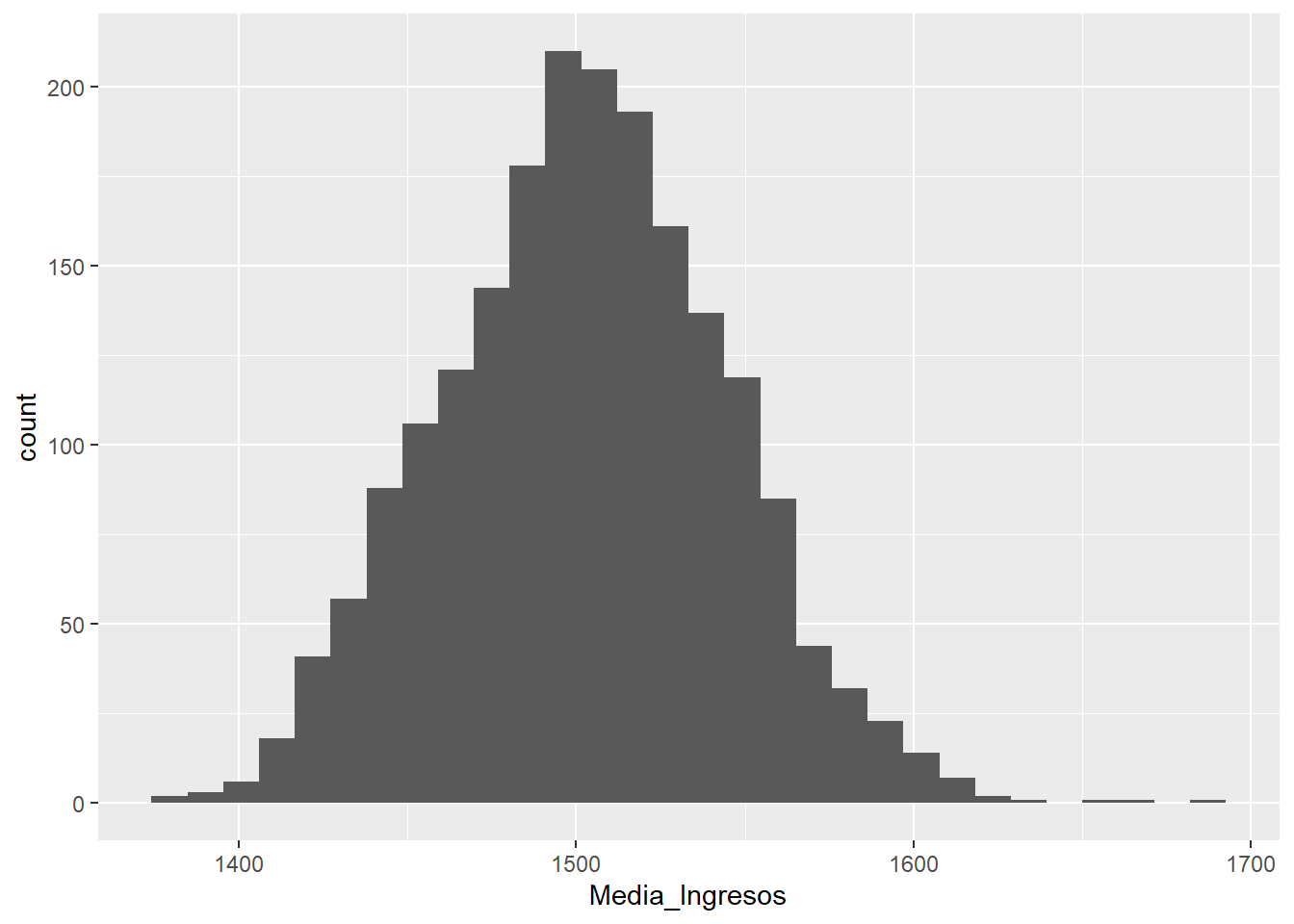
Imagina que el ejercicio de extraer varias muestras y calcular sus medias se repitiera numerosas veces.
Después, en cada repetición, almacenáramos las medias obtenidas en una tabla.
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
Este patrón denominado distribución normal tiene ciertas particularidades que valen la pena explorar.
Importante
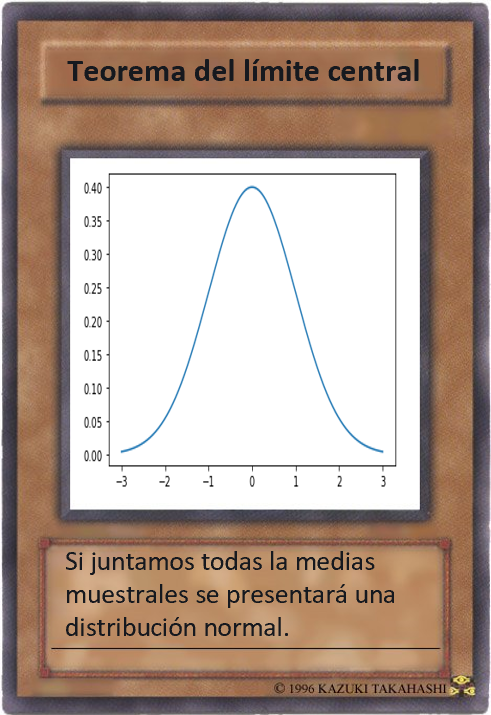
El teorema del límite central dice que si tomamos suficientes muestras aleatorias grandes de una población, la distribución de las medias de esas muestras será una distribución normal, sin importar cómo se vea la distribución original de la población. Esta es la base de una rama importante de la estadística denominada estadística paramétrica.
4.3.5 Distribución normal
Que una variable posea distribución normal nos permite predecir las proporciones de casos que se encuentran en ciertos rangos, partiendo de la media.
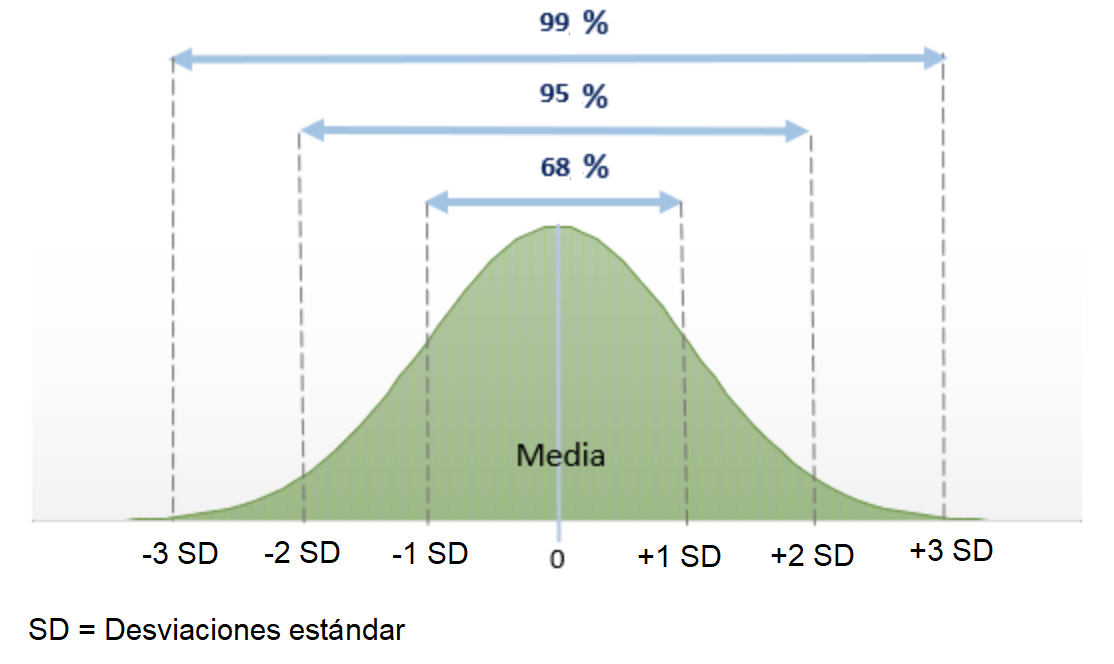
La principal: cerca de la totalidad de observaciones están distribuidas +- 3 desviaciones estándar (puntuaciones Z) respecto de su media.
Como se ve en la figura, son 4 los principios:
50% de las puntuaciones caen encima de la media y 50% debajo;
Prácticamente todas las puntuaciones caen dentro de 3 SD a partir de la media en ambas direcciones (en realidad el 99.7%);
Cerca del 95% de las puntuaciones de una variable normalmente distribuida caen dentro de una distancia de +- 2 SD respecto de la media; y
Alrededor del 68% de las puntuaciones caen dentro de una distancia de +-1 SD respecto de la media.
Ahora bien, si aplicamos este principio a la distribución de medias muestrales, esto varía ligeramente.
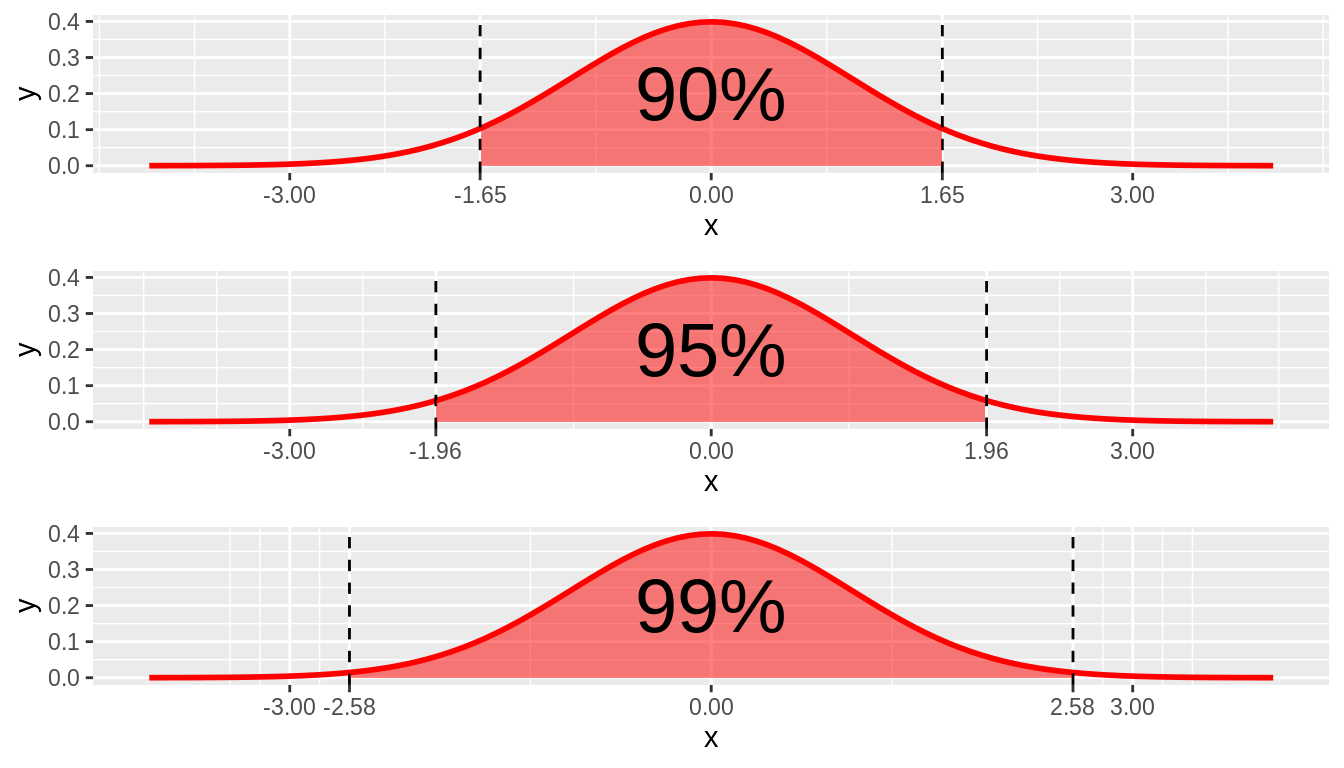
Aquí afirmamos que el 95% de esas medias muestrales que hemos obtenido se ubicarían en el rango que consta de media - 1.96 errores estándar y media + 1.96 errores estándar. Asimismo, podemos calcular el rango en el que se encontraría el 99% (2.58) y el 90% (1.65).
Estos números, que se utilizan para multiplicar el error estándar, son conocidos como valores críticos.
Importante
Como podrás ver, cuando hablamos de distribución de medias muestrales usamos el término error estándar, en lugar de desviación estándar. Básicamente es una medida particular para ver dispersión de esas medias. \[s_{\hat{x}} = \frac{s}{\sqrt{n}}\]
4.3.6 Un intervalo que contiene la media poblacional
Siguiendo este principio (TLC) sumado a lo predecible que es la distribución de una variable que sigue una distribución normal, podemos aplicar lo visto en nuestra primera muestra.
Primero recordamos cual era nuestra media:
media<-mean(muestra1$ingresos)media
[1] 1558.204
Luego, calculamos el error estándar que es igual a la desviación estándar de la muestra sobre la raiz cuadrada del tamaño de la muestra (en nuestro caso 20).
Un intervalo de confianza del 95% de 1461.839 a 1652.366 para la media deingresos indica que, si repetimos el experimento muchas veces, en el 95% de los casos, la media real de la población estará dentro de este rango.
En términos simples, estamos bastante seguros (con un 95% de confianza) de que la media verdadera de la población se encuentra entre 1461.839 y 1652.366.
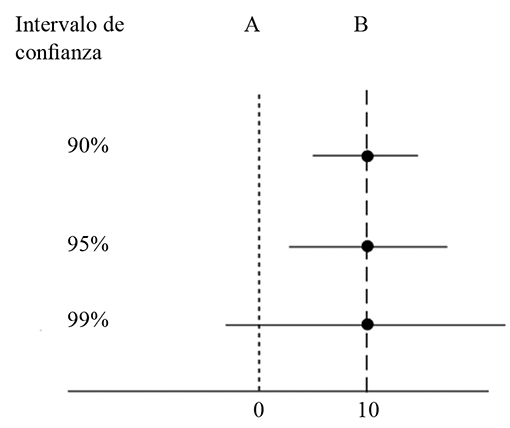
4.3.7 Un trade-off clave: precisión vs confianza
En la inferencia estadística, el trade-off entre precisión y confianza en los intervalos de confianza refleja un equilibrio esencial: mientras mayor es el nivel de confianza deseado (por ejemplo, 95% vs 99%), más amplio será el intervalo de confianza. Esto se debe a que un intervalo más amplio cubre una mayor proporción de los posibles valores verdaderos de la población, aumentando así nuestra confianza en que el intervalo incluye la media real.
Sin embargo, este aumento en la confianza viene a costa de la precisión, ya que un intervalo más amplio ofrece menos precisión sobre dónde se ubica exactamente esa media. Por el contrario, un intervalo más estrecho proporciona una estimación más precisa de la media, pero reduce la confianza de que el intervalo efectivamente contenga la media poblacional. Por lo tanto, la elección del nivel de confianza y del tamaño del intervalo debe considerar cuidadosamente el contexto y las necesidades específicas del análisis.
4.4 Ejercicio 1: ENADES 2022
El Instituto de Estudios Peruanos, por encargo de Oxfam en Perú, elaboró la I Encuesta Nacional de percepción de Desigualdades – ENADES 2022. Este estudio pone a disposición del público el análisis estadístico más completo a la fecha sobre la percepción de las diferentes formas de desigualdad en el Perú.
Además de factores económicos, la presente encuesta incluye indicadores que permiten medir la magnitud de una serie de brechas sociales y políticas: desde diferencias de género, clase y relaciones étnico-raciales, hasta dimensiones subjetivas de la desigualdad y sus vínculos con orientaciones políticas. Como se muestra a lo largo del informe, la base de datos de este proyecto provee herramientas valiosas a expertos de diferentes campos, tanto académicos como profesionales, estudiantes y personas interesadas en el análisis multidimensional de la desigualdad en el país.
Puedes abrir el cuestionario de la encuestas aquí.
library(haven)library(tidyverse)enades<-read_spss("data/ENADES_2022.sav") # Con esta función abrimos archivos de SPSS# enades<-read_spss("https://github.com/ChristianChiroqueR/banco_de_datos/raw/main/ENADES_2022.sav")
Recuerda que si en un primer momento te pierdes un poco entre los nombres de las variables, eso quiere decir que tienes que leer el cuestionario y el diccionario de variables!
4.4.2 Identificar una variable numérica
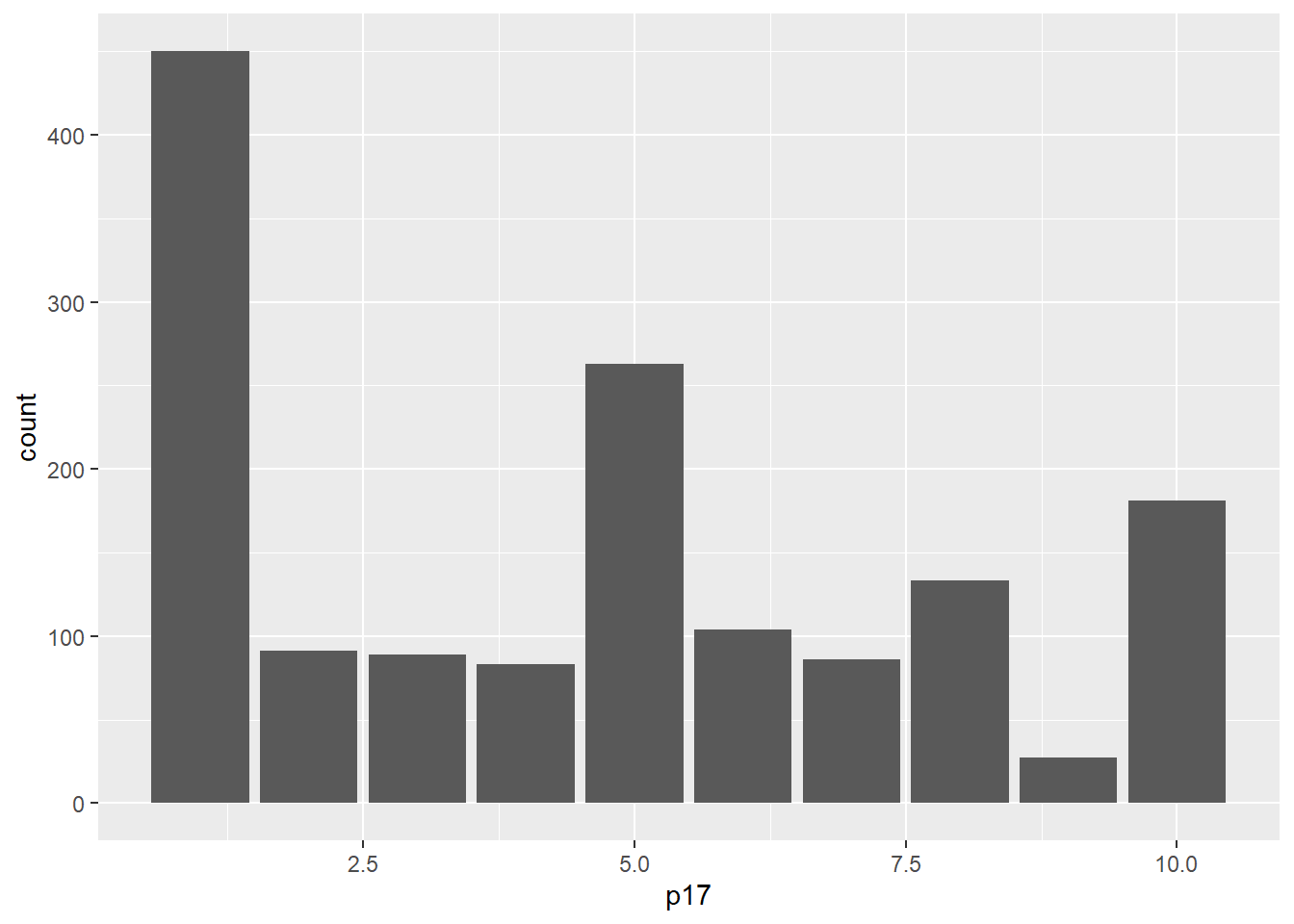
Elijamos la variable P17:
En una escala del 1 al 10, en la que 1 es “Totalmente inaceptable” y 10 es “Totalmente aceptable”. ¿Hasta qué punto es aceptable la desigualdad en el Perú? Dígame un número de 1 a 10, recuerde que 1 es “Totalmente inaceptable” y 10 es “Totalmente aceptable (RESPUESTA ESPONTÁNEA)
La convertimos en numérica.
enades$p17<-as.numeric(enades$p17)
Solicitamos los estadísticos descriptivos para darle una primera mirada.
summary(enades$p17)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.000 1.000 5.000 4.571 7.000 10.000 23
Podemos graficarlo
enades |>ggplot() +aes(x=p17)+geom_bar()
4.4.3 Cálculo del estimador puntual
Calculamos el estimador puntual, en este caso, la media muestral.
mean(enades$p17, na.rm =TRUE)
[1] 4.571334
Tienes que recordar lo básico de este:
Es solo una aproximación del verdadero valor poblacional, y su precisión puede variar dependiendo del tamaño y calidad de la muestra, entre otros factores.
Es por ello que, a menudo, se complementa con intervalos de confianza para ofrecer un rango de valores en los que es probable que se encuentre el verdadero parámetro poblacional.
4.4.4 Cálculo del IC al 95%
MANUAL
Recordemos qué necesitamos para calcular el intervalo de confianza de una media.
Necesitamos la media muestral (mean) de esa única muestra que obtuvimos de la población, la desviación estándar (sd) y el tamaño de muestra que tenemos (n).
Así también, necesitamos elegir qué nivel de confianza vamos a tomar (recuerdas los intervalos de la distribución normal? y cómo se aplicaría a distribuciones muestrales?), es decir, si vamos al 95% (1.96) o algún otro nivel.
Por lo pronto, hemos obtenido un error estándar con un valor de 0.08009848.
El error estándar, en su esencia, nos brinda una medida de cuánta variabilidad podemos esperar en nuestras estimaciones si repitiéramos el muestreo muchas veces. Cuando interpretamos un error estándar específico, como 0.08009848 podemos considerar lo siguiente:
Un error estándar de 0.08009848 sugiere que, si tomáramos múltiples muestras del mismo tamaño de la población y calculáramos la estadística de interés (por ejemplo, la media) para cada muestra, esperaríamos que la mayoría de esas estadísticas estuvieran dentro de 0.08009848 unidades de la estadística media de todas esas muestras.
En otras palabras, el valor de 0.08009848 nos da una idea de la “precisión” de nuestra estimación basada en una sola muestra. Una estimación con un error estándar más pequeño generalmente se considera más “precisa” que una con un error estándar más grande, porque indica menos variabilidad entre las estimaciones de diferentes muestras.
Ahora sí, una vez calculado el error estándar podemos calcular los límite inferior o superior. Recuerda que debemos aplicar la fórmula y que la única diferencia para calcular el límite inferior y superior es el signo:
limite_inferior<- media - (z*error_estandar)limite_superior<- media + (z*error_estandar)
Los presentamos:
limite_inferior
[1] 4.414341
limite_superior
[1] 4.728327
Con ello podemos concluir que: Con un 95% de confianza, podemos afirmar que la media poblacional de la aceptación de la desigualdad en el Perú (que va del 1 al 10) se encuentra entre 4.414341 y 4.728327.
Esto lo podemos interpretar también de las siguientes forma:
Estoy 95% seguro de que el promedio de aceptación de la desigualdad en el país real (es decir el parámetro) se encuentra entre 4.414341 y 4.728327.
Si realizara este estudio 100 veces, 95 veces obtendré un promedio de aceptación de la desigualdad dentro de este intervalo: 4.414341 y 4.728327.
CON LA FUNCIÓN ciMean()
Una vez que hemos navegado por el proceso de calcular un intervalo de confianza de manera manual, utilizando la fórmula tradicional, es hora de introducir herramientas que simplifiquen y agilicen este proceso en el mundo real del análisis de datos. Para ello, en R, utilizaremos el paquete lsr y, específicamente, la función ciMean. Esta función está diseñada para calcular automáticamente el intervalo de confianza para la media de un conjunto de datos. Al proporcionarle una serie de datos como entrada, ciMean nos devuelve el rango en el que, con un nivel de confianza específico (por defecto, 95%), esperamos que se encuentre la verdadera media poblacional. Es una herramienta poderosa que combina precisión con eficiencia, permitiéndonos centrarnos en la interpretación y aplicación de nuestros resultados.
library(lsr)ciMean(enades$p17, na.rm = T)
2.5% 97.5%
[1,] 4.413023 4.729645
Es el mismo resultado que obtuvimos arriba. Como te puedes dar cuenta, si hemos recorrido este camino (medio tedioso) es para que te quede claro cómo se obtienen esos dos números que llamamos intervalos de confianza y de qué depende en la práctica al utilizar una muestra real.
4.4.5 Barras de error
Tras calcular el intervalo de confianza, una práctica recomendada es visualizarlo gráficamente. El representar este intervalo en un gráfico no solo nos facilita la comprensión de su significado, sino que también nos proporciona una perspectiva visual de dónde se sitúa nuestra estimación y el rango dentro del cual esperamos que se encuentre el verdadero valor poblacional. Al observar el intervalo de confianza en un gráfico, podemos tener una idea más intuitiva y clara de la precisión y confiabilidad de nuestra estimación, así como de la variabilidad asociada a ella.
En el contexto de intervalos de confianza, las barras de error se utilizan para representar el nivel de incertidumbre en una estimación puntual del parámetro poblacional. Un intervalo de confianza es un rango de valores plausible para el valor del parámetro poblacional, y se construye a partir de una muestra aleatoria y un nivel de confianza específico.
Las barras de error en un gráfico de intervalos de confianza se construyen a partir de los límites superior e inferior del intervalo de confianza. Generalmente se dibujan líneas verticales que se extienden desde el valor estimado del parámetro (que puede ser una media, una proporción, una diferencia de medias, etc.) hasta los límites del intervalo de confianza.
Por ejemplo, si se estima la media de una variable a partir de una muestra y se desea construir un intervalo de confianza al 95%, las barras de error se construirán a partir del límite inferior y superior del intervalo de confianza, que contendrán el verdadero valor de la media poblacional con una probabilidad del 95%.
Las barras de error en un gráfico de intervalos de confianza pueden ser útiles para comparar la precisión de las estimaciones entre diferentes grupos o condiciones. Si las barras de error son muy pequeñas, esto sugiere que la estimación es muy precisa y que hay una alta confianza en la validez del intervalo de confianza. Por otro lado, si las barras de error son grandes, esto sugiere que la estimación es menos precisa y que hay una mayor incertidumbre en el intervalo de confianza.
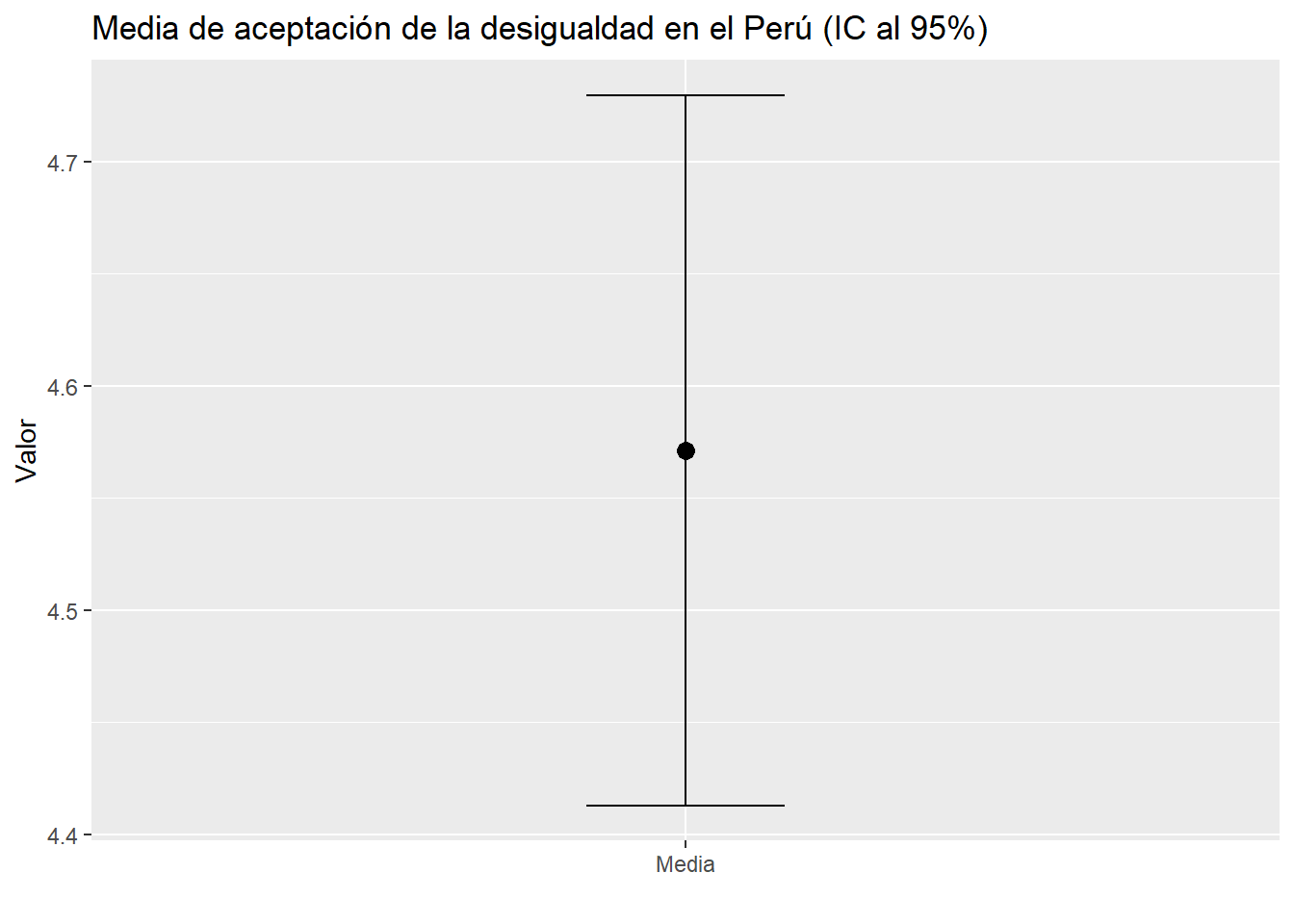
Podemos utilizar ggplot()!
mediaEintervalos<-enades %>%summarise(mean =mean(p17, na.rm =TRUE), #Utilizamos summarise y pedimos la media,ci_lower =ciMean(p17, na.rm = T)[1], # También el PRIMER ELEMENTO de la función ciMeanci_upper =ciMean(p17, na.rm = T)[2]) #Y el SEGUNDO ELEMENTO de la función ciMeanmediaEintervalos
# A tibble: 1 × 3
mean ci_lower ci_upper
<dbl> <dbl> <dbl>
1 4.57 4.41 4.73
mediaEintervalos %>%ggplot() +aes(x ="Media", y = mean)+geom_point(size =3) +geom_errorbar(aes(ymin = ci_lower, ymax = ci_upper), width =0.2) +labs(title ="Media de aceptación de la desigualdad en el Perú (IC al 95%)", y ="Valor", x ="")
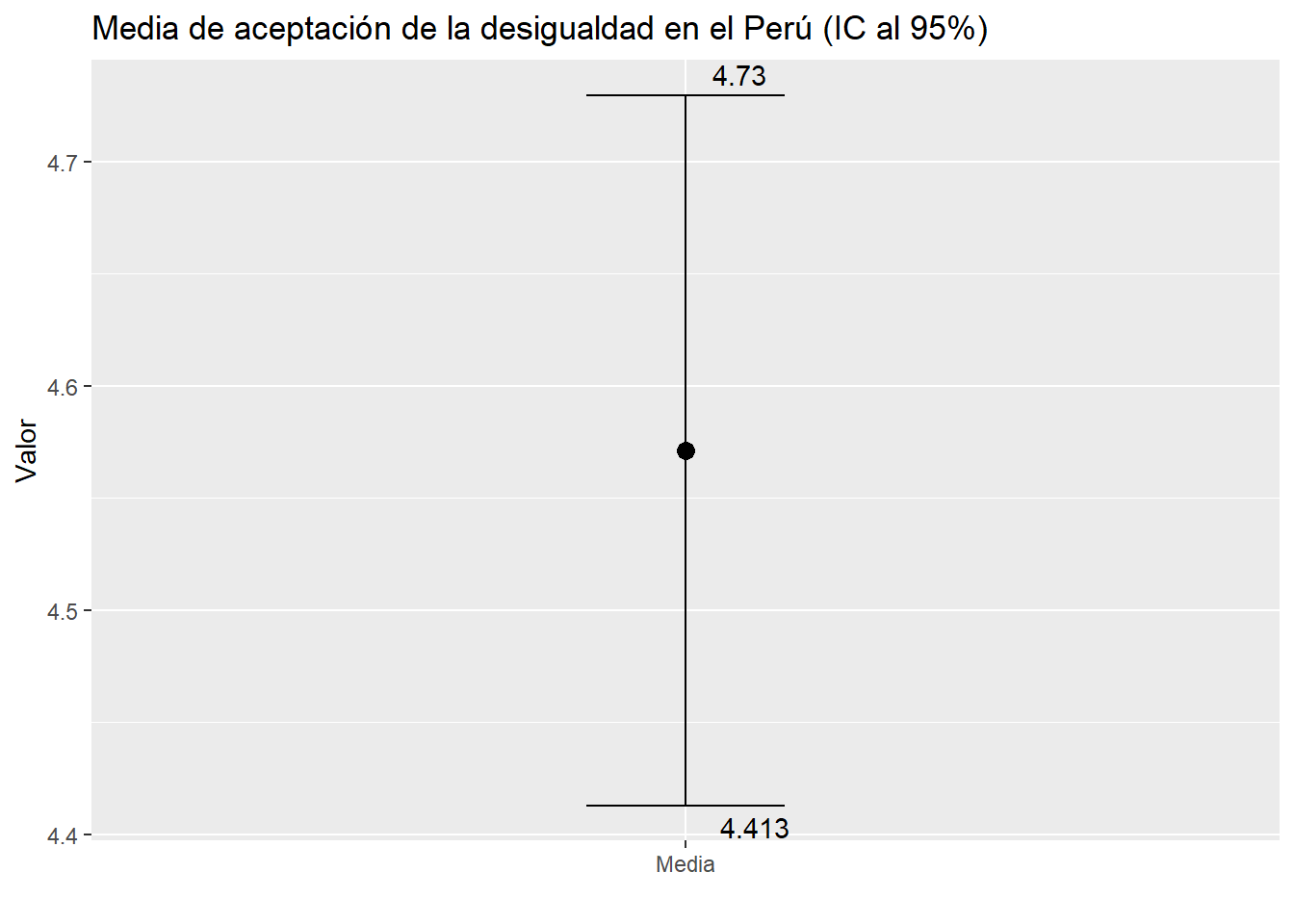
Puedes incluir más detalle y detallar los límites inferior y superior:
mediaEintervalos %>%ggplot() +aes(x ="Media", y = mean) +geom_point(size =3) +geom_errorbar(aes(ymin = ci_lower, ymax = ci_upper), width =0.2) +geom_text(aes(label =round(ci_lower, 3), y = ci_lower), vjust =1.5, hjust =-0.5) +# Etiqueta para el límite inferiorgeom_text(aes(label =round(ci_upper, 3), y = ci_upper), vjust =-0.5, hjust =-0.5)+# Etiqueta para el límite superiorlabs(title ="Media de aceptación de la desigualdad en el Perú (IC al 95%)", y ="Valor", x ="")